
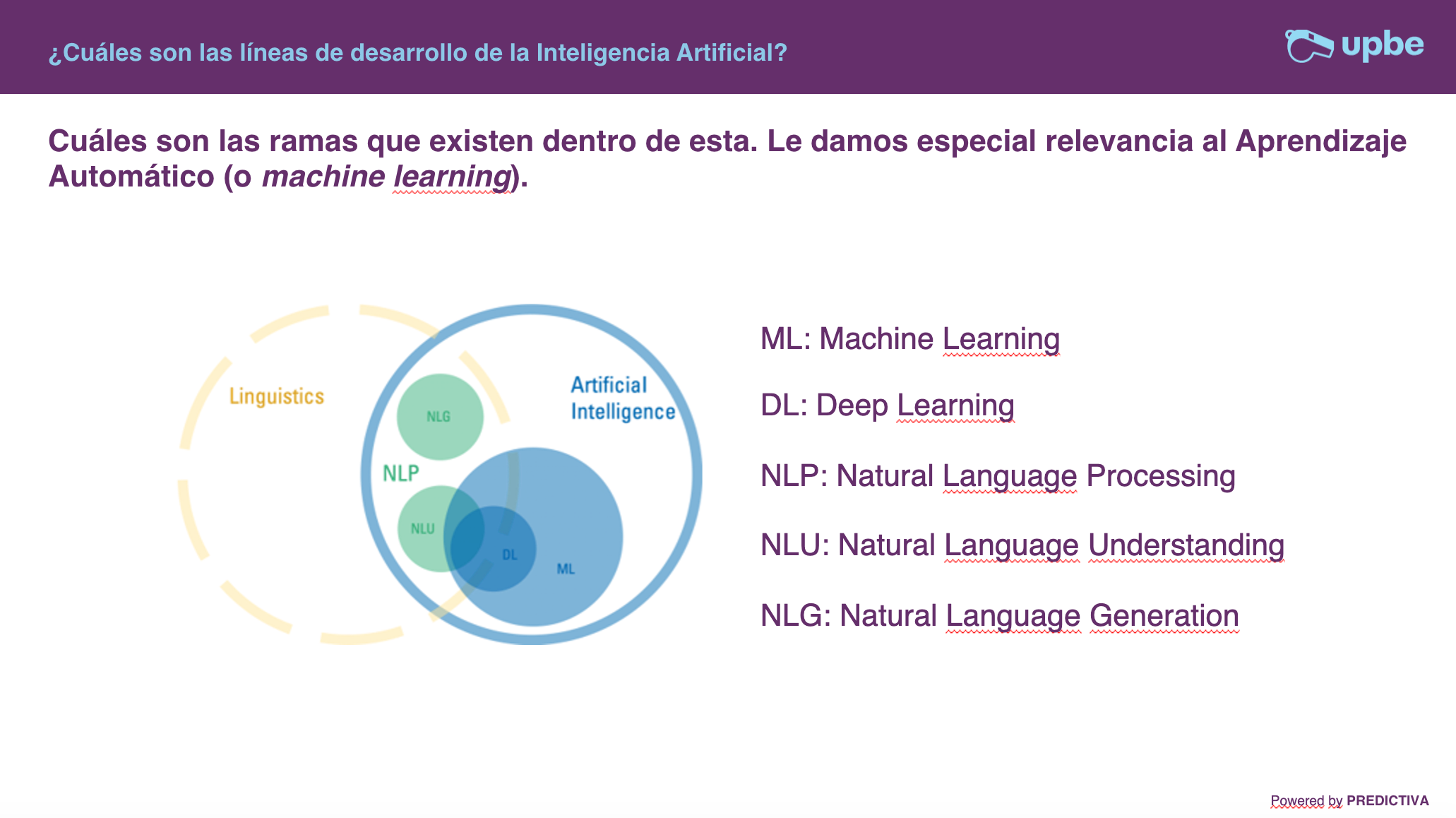
En la serie de artículos que estamos compartiendo sobre la tecnología en la que se apoya Upbe, ya hemos hablado de cuestiones fundamentales. Como las diferencias entre Inteligencia Artificial, Machine Learning y Deep Learning. O las que existen entre NLP, NLU y NLG. Hoy toca hablar de ASR.
En este último hablábamos del potencial de estas técnicas en los contact centers, detallando los entornos de herramientas y técnicas que acompañan el NLP. En estos entornos se sitúan los sistemas de Speech Technologies, que son dos:
- Sistemas de reconocimiento del habla (ASR)
- Sistemas de síntesis del habla (Text-To-Speech)
Estos sistemas hacen de interfaz entre las personas y los sistemas NLP. Estas tecnologías son el canal que permite la comunicación entre humanos y máquinas. Para el caso del ASR permite la comunicación de un emisor humano y un receptor máquina permitiendo que módulos NLP reciban una transcripción de texto. Y los sistemas Text-To-Speech establecen una comunicación donde la máquina es el emisor y el humano el receptor convirtiendo el texto en discurso hablado.
Hoy vamos a profundizar en los sistemas de reconocimiento del habla (ASR – Automatic Speech Recognition). Estos sistemas están totalmente integrados en nuestro día a día. Como tecnología, está validada ya que son sistemas en los que se apoyan los asistentes de voz (de Apple, Google o Amazon) o aplicaciones de mensajería (para dictados, por ejemplo).
¿Qué es el ASR?
En corto: el audio que entra se convierte en texto. Para convertirlo, entre medias, el audio tiene que convertirse a un archivo que pueda ser leído por la máquina. Esto significa que la herramienta trabaja con modelos acústicos y del lenguaje.
Los modelos acústicos contienen una representación estadística de un sonido o fonema. Se crea usando muchos datos acústicos. El modelo de lenguaje representa estadísticamente la probabilidad en las que podrían ocurrir o suceder las palabras. Es decir, estos modelos estiman la probabilidad de que aparezcan ciertos fonemas que significan ciertas palabras.
El objetivo del modelo acústico es crear un conjunto de probabilidades que representen todos los sonidos del lenguaje que se deben reconocer. Para crear los modelos acústicos se tiene que determinar antes qué sonidos se quieren representar o qué modelo probabilístico se utilizará.
Esos modelos determinan la relación que hay entre las señales de audio y los fonemas del lenguaje. Mientras tanto, el modelo concluye qué sonidos encajan con qué palabras y frases.
En pasos:
- Le hablas a un software.
- El dispositivo crea archivos de texto.
- El archivo es limpiado por el software de ruidos.
- El archivo de divide en fonemas.
- El sistema ASR, por probabilidad basada en el modelo de lenguaje, une los fonemas y transcribe el audio original a texto.
Ahora que lo ha entendido, el sistema ASR puede responder generando una transcripción entendiendo tu contexto. Y responder con sentido. Eso es lo fundamental, y más aplicado al entorno de análisis en el que una gran empresa o contact center. Convertir datos no estructurados en información estructurada, para analizarla, es diferencial para el negocio.

En este sentido, también es importante resaltar que un sistema ASR es capaz de, con la suite de tecnología adecuada, interpretar jergas, usos del lenguaje particulares o acentos. Este es un enfoque con el que actualmente trabajamos en Upbe, porque sabemos que hay mucha inteligencia de negocio en interpretar adecuadamente esta información.
¿Qué aplicaciones tienen los sistemas de reconocimiento del habla?
Las aplicaciones de los sistemas ASR (Automatic Speech Recognition) son muy diversas. Como decíamos al principio, es una tecnología absolutamente integrada en nuestro día a día. Aquí puedes ver varios ejemplos:
- Telefonía: sistemas de dictado, activación de interfaces personales, transcripciones de mensajes, búsquedas por voz o traducciones automáticas son algo común basado en sistemas de reconocimiento del habla.
- Automoción: cualquier instrucción de voz que un coche es capaz de entender y gestionar, como hacer llamadas, poner la radio o incluso abrir una aplicación concreta.
- Domótica: todo tipo de hardware que recibe instrucciones y reacciona a órdenes concretas. Aquí están tanto Alexa como Google Home. O cualquier instrucción para apagar o encender luces o regular el termostato.
- Aplicaciones en el ámbito militar. Para poder tener autonomía e independencia durante el vuelo, existe mucha tecnología basada en sistemas ASR para cambiar frecuencias de transmisión, iniciar modos de auto-vuelo o desplegar parametros para establecer coordenadas de vuelo.
- Audiovisual: es común utilizar tecnologías de Speech Recognition para subtitular programas, tanto en directo como on-demand.
- Ámbito judicial: existen iniciativas muy interesantes para optimizar la transcripción de información tan necesaria en el sector o para búsqueda de archivos.
- Call Center: centrado en el análisis de voz de cliente, en la automatización de controles de calidad y compliance, o en la mejora de efectividad en campañas de venta.
- Y mucho más, como sistemas de IVR, robótica, aplicacions en la industria del video juego, traducciones automáticas, etc.
¿Cómo puede ASR mejorar la eficiencia de las llamadas?
Viendo el anterior listado, que puede ampliarse más, de las aplicaciones de los sistemas ASR, se entiende su relevancia. Toda esta información, la que podemos pasar de un audio a texto, es muy común y compleja. Tanto que sus aplicaciones, en el caso del contact center, suponen revolucionar por completo una industria o sector.
Parece simple transcribir un audio dictado, pero esto por lo general no ocurre en las llamadas de tu call center. Existen muchas interferencias que los sistemas ASR son capaces de separar y analizar. Hay contextos de mucha complejidad, con grabaciones de audio muy comprimidas, con solapamientos de voces o ruidos de fondo que distorsionan lo que hay en los audios.
Además, por lo general, los interlocutores hablan a distintas velocidades, con diversidad de emociones e incluso de acentos o jerga. Esto es lo que hace que el proceso sea complejo y necesite la tecnología a su disposición.
¿Cómo sabemos que el sistema ASR funciona?
Existen dos métricas para evaluar si nuestro sistema funciona adecuadamente:
- Word error rate, que mide el porcentaje de caracteres erróneos. Lo hace analizando el número se palabras borradas, sustituidas o insertadas que tenemos que intervenir para conseguir la frase real transcrita.
- Sentence error rate, que mide el porcentaje de frases intervenidas en un texto.
Por lo general, la más válida o utilizada es el WER (word error rate). ¿Cómo se calcula? Para calcular el WER tenemos que calcular el número de palabras sustituidas, insertadas o eliminadas entre la versión correcta del texto y la versión que sale del sistema ASR tal cual. En este caso hemos hecho la prueba con la funcionalidad de dictado de una marca estándar de telefonía móvil:

En un ejemplo en el que las palabras subrayadas en amarillo están mal (y las amarillas son la opción correcta), el WER es del 9,4%. Hemos entendido que hay 5 modificaciones entre un total de 53 palabras.
Ejemplos de implementación exitosa de ASR
El reconocimiento automático de voz (ASR) ha sido una herramienta clave para las empresas de centro de contacto como servicio (CCaaS) en su búsqueda por automatizar y mejorar el procesamiento de consultas de clientes. Al utilizar soluciones ASR, las empresas pueden ofrecer una atención al cliente más flexible y satisfactoria, y tener acceso a tecnologías avanzadas y análisis basados en las mejores prácticas de la industria.
Aunque la tecnología de reconocimiento de voz antigua era inexacta debido a la jerga específica de la industria y la mala calidad de las llamadas, el aprendizaje profundo de extremo a extremo ha permitido la creación de modelos precisos con nuevos datos. Las soluciones ASR se dividen en dos categorías: reconocimiento de voz y comprensión del habla. Ambas son especialmente relevante para el centro de llamadas, ya que ayuda a mejorar el reconocimiento de voz y la comprensión del significado detrás de lo que se está diciendo.
El análisis de voz puede ser implementado en un centro de llamadas para automatizar las siguientes funciones:
- La verificación de calidad
- La moderación de contenido
- La identificación de palabras desencadenantes
- La habilitación del autoservicio
- Etc.
Sin embargo, la implementación de análisis de voz en un centro de llamadas también presenta desafíos, como la transcripción precisa y rentable de las conversaciones, la generación de información significativa a partir de los datos de voz transcritos y la aplicación efectiva de conocimientos para mejorar los resultados finales. Para superar estos desafíos, las empresas deben invertir en herramientas de análisis precisas y predictivas y encontrar socios adecuados para ejecutar estas iniciativas con éxito.
A pesar de estos desafíos, el avance del aprendizaje profundo ha hecho posible la transcripción de voz a texto con alta precisión a nivel de la nube, lo que hace que esta tecnología sea más accesible para las empresas haciendo que el análisis de voz pueda proporcionar información valiosa para las empresas y mejorar la satisfacción del cliente en el centro de llamadas.

Para mejorar la eficiencia en un Call Center, es fundamental implementar tecnologías avanzadas como los sistemas de reconocimiento automático del habla (ASR, por sus siglas en inglés). Estos sistemas pueden transcribir y analizar audio en situaciones complejas, como audios muy comprimidos, solapamientos de voces o ruidos de fondo, y diversidad en la velocidad del habla, emociones, acentos o jerga. Estos sistemas son capaces de lidiar con todas estas interferencias y complejidades, revolucionando la eficiencia y la efectividad de un call center al transformar la información de audio en datos textuales útiles y analizables.
El ASR, o Reconocimiento Automático del Habla, en un Call Center es una tecnología que convierte el audio entrante en texto. Esta transformación se realiza a través de modelos acústicos y de lenguaje. Los modelos acústicos contienen una representación estadística de un sonido o fonema y se crean utilizando grandes volúmenes de datos acústicos. El modelo de lenguaje, por su parte, representa estadísticamente la probabilidad de ocurrencia de palabras. Juntos, estos modelos estiman la probabilidad de aparición de ciertos fonemas que conforman palabras específicas, determinando la relación entre las señales de audio y los fonemas del lenguaje, y concluyendo qué sonidos corresponden a qué palabras y frases.
El ASR funciona en varios pasos. Primero, el usuario habla a un software. A continuación, el dispositivo convierte lo que se ha dicho en archivos de texto. Estos archivos son limpiados por el software para eliminar ruidos. Luego, el archivo se divide en fonemas o unidades de sonido. Finalmente, el sistema ASR utiliza modelos de lenguaje para unir los fonemas y transcribir el audio original a texto. El ASR es capaz de generar una transcripción comprensible y responder con sentido al contexto proporcionado. La principal utilidad de este sistema es convertir datos no estructurados en información estructurada para análisis, lo que es particularmente útil en entornos como los call centers. Con la tecnología adecuada, un sistema ASR puede interpretar jergas, usos particulares del lenguaje y acentos, lo que permite un análisis de negocio más preciso y completo.
La eficiencia en un Call Center se refiere a la capacidad del centro para manejar una gran cantidad de llamadas y consultas de los clientes de manera efectiva y oportuna. Implica optimizar los procesos y utilizar las herramientas y tecnologías adecuadas para minimizar los tiempos de espera, resolver las consultas de los clientes rápidamente, mantener la calidad del servicio y garantizar la satisfacción del cliente.


8 Comments